
Feb 26th 2026
Bridging the Gap Between Simulation and Reinforcement Learning: Introducing train_fmu_gym
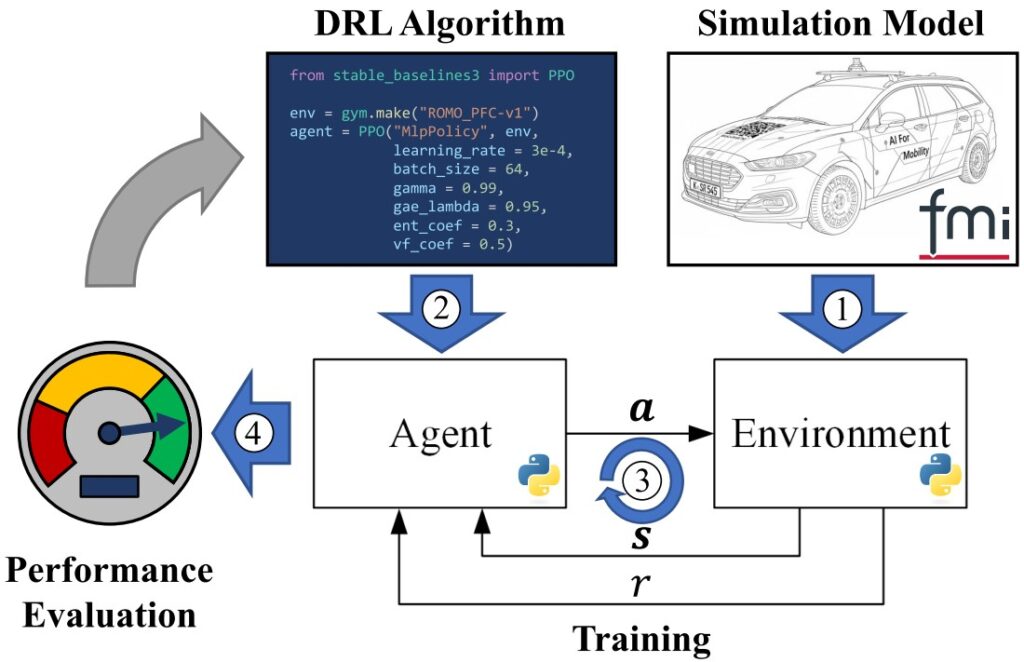
The train_fmu_gym toolchain represents a significant advancement in applying reinforcement learning to multi-physical systems by bridging existing simulation models with modern Deep Reinforcement Learning (DRL) frameworks. This framework, as shown below, enables researchers and engineers to leverage existing simulation models by using the Functional Mock-up Interface (FMI) standard (1) to create gymnasium-compatible training environments (3) including their DRL algorithms (2) with a comprehensive performance evaluation (4).
Flexible Observation and Reward Management
The toolchain implements a sophisticated versioning system for environments, where each version corresponds to a specific observation set, reward function, and truncation condition. This design enables systematic experimentation with different reward formulations and observation spaces without breaking existing trained agents. Observations can include signal histories, and the framework automatically normalizes observations using nominal values from the FMU metadata.
Scenario-Based Training and Evaluation
train_fmu_gym introduces a powerful scenario management system that defines different environmental conditions through FMU parameters and initial values. This capability is crucial for training robust agents across varying conditions, such as different vehicle paths, payload configurations, or mission profiles. The framework integrates the Modelica Credibility Library to support uncertainty quantification, allowing parameters to be sampled from probability distributions during training episodes.
Comprehensive Evaluation Framework
Beyond simple cumulative reward tracking, train_fmu_gym provides dedicated evaluation metrics functionality. Users can define custom performance metrics, such as energy consumption, maximum tracking error, or task completion time, in a standard Python file. The framework supports parallelized evaluation across multiple scenarios and agents, making large-scale performance assessment computationally feasible.
Streamlined CLI Workflow
The toolchain is controlled through a streamlined command-line interface (CLI) designed to manage the entire RL lifecycle. By using the CLI, users can initialize training environments, launch agent training sessions that include automated hyperparameter sweeps, and calculate performance against custom engineering metrics. Additional utilities support the analysis of results, enabling visualization of an agent’s learning progress and simulation of its final behavior.
Cross-Platform Compatibility
train_fmu_gym supports both Windows and Linux environments, with intelligent handling of platform-specific FMU binaries and storage paths. This enables workflows where training occurs on Linux compute clusters while analysis happens on Windows workstations, utilizing shared network storage for trained agents.
Integration with State-of-the-Art RL Tools
The framework seamlessly integrates with Stable Baselines3 for RL algorithms and FMPy for FMU integration. Users can configure multiple hyperparameter combinations in JSON configuration files, and the toolchain automatically launches parallel training runs for each combination. Training progress is monitored and stored with unique IDs, maintaining a complete history of all training experiments.
Built for Iterative Development
train_fmu_gym recognizes that RL development is inherently iterative. The framework provides commands like tfg add_env_version to create new environment versions when exploring different reward functions, and maintains strict versioning to prevent inconsistencies between trained agents and their environments. This design philosophy ensures reproducibility and prevents common pitfalls in RL research workflows.
train_fmu_gym addresses a critical gap in applying reinforcement learning to engineering systems by making existing simulation assets immediately usable for RL training. By reducing the technical barriers to FMU-based RL and providing a complete workflow from setup through evaluation, the toolchain accelerates research and enables practical deployment of RL controllers for complex multi-physical systems.
Get Started
Ready to try it out? You can access toolchain and documentation directly at the repository:
https://codebase.helmholtz.cloud/dlr-vsdc/train_fmu_gym
Reference
For a deep dive into the methodology and architecture, please refer to the accompanying paper:
J. Ultsch, K. Ahmic und J. Brembeck, „train_fmu_gym: A Functional Mock-up Unit-based Framework to Train Reinforcement Learning Agents for Multi-Physical Systems,“ IEEE Access, p. 1–1, 2025, doi: 10.1109/access.2025.3636787.
Mit einem Freund teilen