train_fmu_gym

The train_fmu_gym library provides a framework to generate and manage Functional Mock-up Unit (FMU) based reinforcement learning (RL) training environments implementing the gymnasium API. The library enables users to leverage preexisting simulation models for deep reinforcement learning by utilizing the FMI standard, supporting both FMI 2.0 and FMI 3.0 Co-Simulation FMUs. train_fmu_gym offers automatized environment generation from FMUs, handling of different reward implementations and observation sets, definition and utilization of scenarios including uncertain scenarios via Modelica Credibility integration, as well as introduction of evaluation metrics to assess trained agents. The training process is supported by more than 20 command line interface (CLI) user functions, enabling fast setup, training and evaluation of RL agents without the need to write extensive additional Python code. train_fmu_gym is compatible with both Linux and Windows platforms. A community edition with limited input/output support is freely available under the CC BY-NC-ND 4.0 license; for the full version without restrictions, please contact the DLR Institute of Vehicle Concepts, Department of Vehicle System Dynamics and Control.
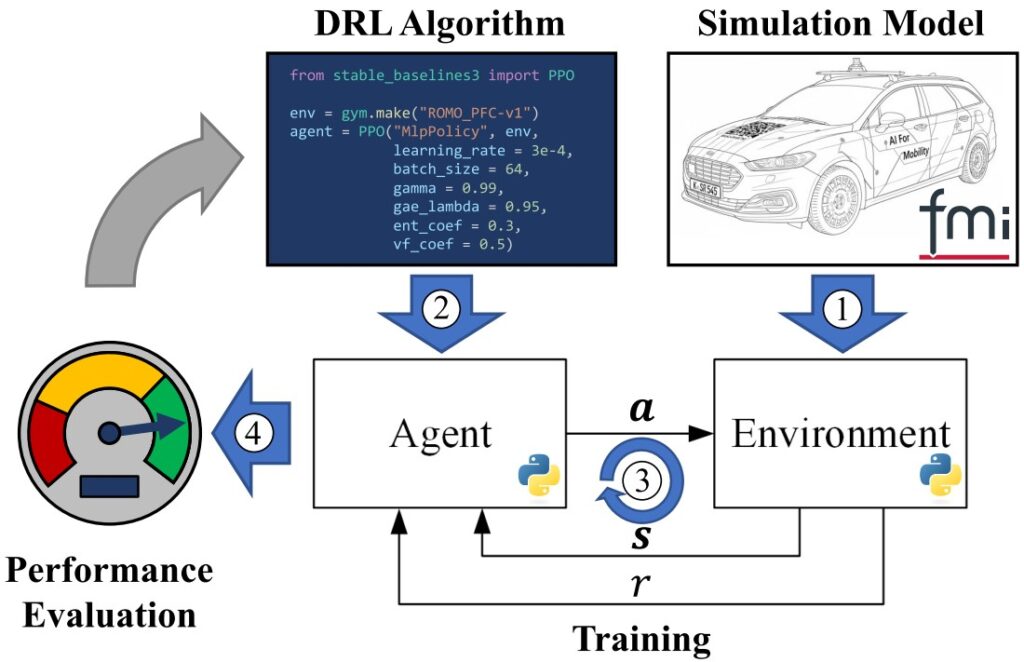
Application Example
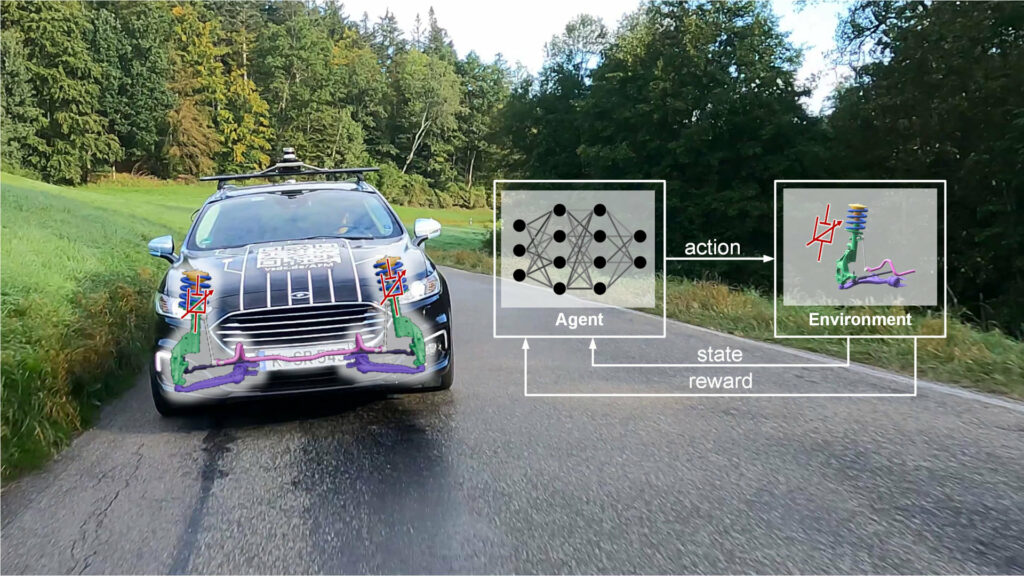
AI based Vertical Dynamics Control
The KIFAHR project demonstrated how a full reinforcement‑learning (RL) toolchain can be used to design and deploy a semi‑active suspension controller that simultaneously maximizes ride comfort and road holding. By converting extensive vehicle‑test data into high‑fidelity training models—both physics‑based and neural‑network‑based—the team automatically trained, validated, and exported RL agents as C code for real‑time execution on an in‑vehicle microcontroller, complete with a safety‑guarding concept. Compared with a state‑of‑the‑art Skyhook & Groundhook controller, the RL‑based controller consistently delivered superior performance across a wide range of driving maneuvers in both simulation and on‑rig tests. The project thus proved that an end‑to‑end RL toolchain not only streamlines controller development but also yields quantitatively better vertical‑dynamics control, paving the way for more automated and adaptable automotive suspension systems.
Features of the Library
+ Flexible Observation and Reward Management
Flexible Observation and Reward Management
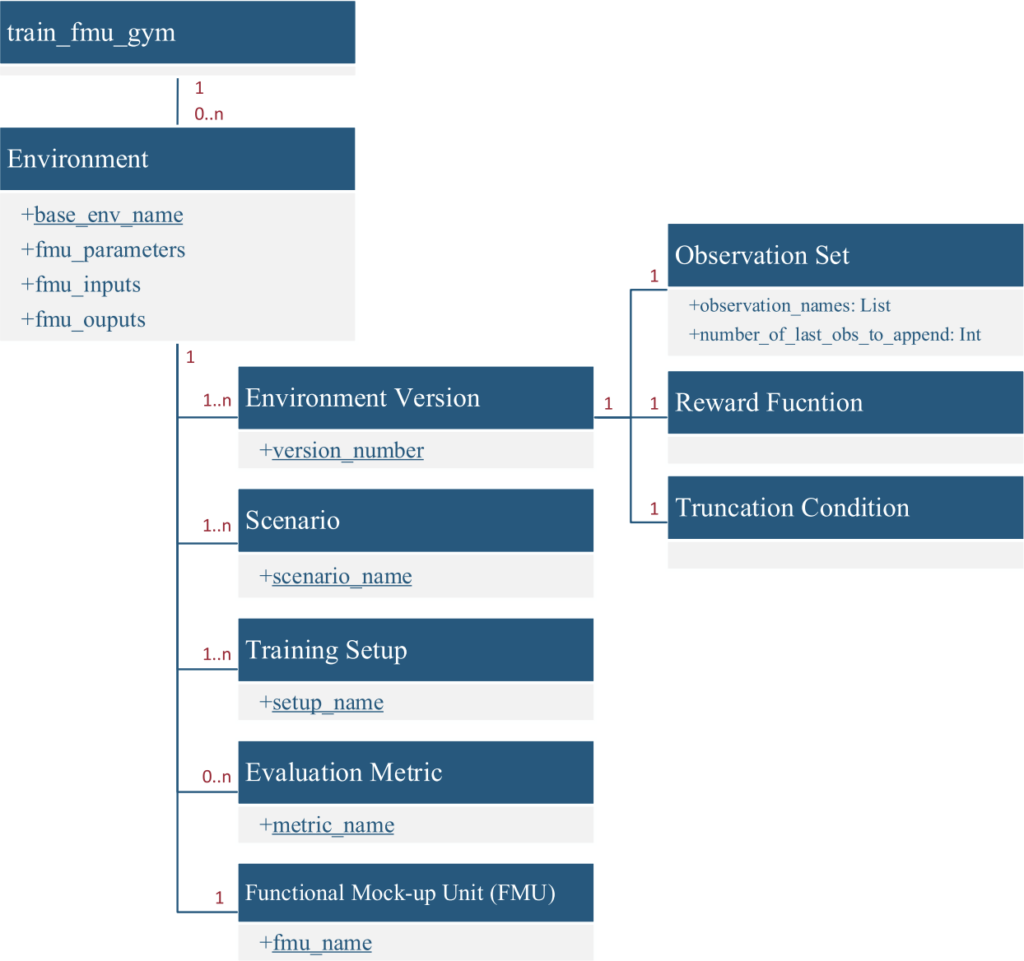
The toolchain implements a sophisticated versioning system for environments, where each version corresponds to a specific observation set, reward function, and truncation condition. This design enables systematic experimentation with different reward formulations and observation spaces without breaking existing trained agents. Observations can include signal histories, and the framework automatically normalizes observations using nominal values from the FMU metadata.
hide
+ Scenario-Based Training and Evaluation
Scenario-Based Training and Evaluation
train_fmu_gym introduces a powerful scenario management system that defines different environmental conditions through FMU parameters and initial values. This capability is crucial for training robust agents across varying conditions, such as different vehicle paths, payload configurations, or mission profiles. The framework integrates the Modelica Credibility Library to support uncertainty quantification, allowing parameters to be sampled from probability distributions during training episodes.
hide
+ Comprehensive Evaluation Framework
Comprehensive Evaluation Framework
Beyond simple cumulative reward tracking, train_fmu_gym provides dedicated evaluation metrics functionality. Users can define custom performance metrics, such as energy consumption, maximum tracking error, or task completion time, in a standard Python file. The framework supports parallelized evaluation across multiple scenarios and agents, making large-scale performance assessment computationally feasible.
hide
+ Streamlined CLI Workflow
Streamlined CLI Workflow
The toolchain is controlled through a streamlined command-line interface (CLI) designed to manage the entire RL lifecycle. By using the CLI, users can initialize training environments, launch agent training sessions that include automated hyperparameter sweeps, and calculate performance against custom engineering metrics. Additional utilities support the analysis of results, enabling visualization of an agent’s learning progress and simulation of its final behavior.
hide
+ Cross-Platform Compatibility
Cross-Platform Compatibility
train_fmu_gym supports both Windows and Linux environments, with intelligent handling of platform-specific FMU binaries and storage paths. This enables workflows where training occurs on Linux compute clusters while analysis happens on Windows workstations, utilizing shared network storage for trained agents.
hide
+ Integration with State-of-the-Art RL Tools
Integration with State-of-the-Art RL Tools

The framework seamlessly integrates with Stable Baselines3 for RL algorithms and FMPy for FMU integration. Users can configure multiple hyperparameter combinations in JSON configuration files, and the toolchain automatically launches parallel training runs for each combination. Training progress is monitored and stored with unique IDs, maintaining a complete history of all training experiments.
hide
+ Built for Iterative Development
Built for Iterative Development
train_fmu_gym recognizes that RL development is inherently iterative. The framework provides commands like tfg add_env_version to create new environment versions when exploring different reward functions, and maintains strict versioning to prevent inconsistencies between trained agents and their environments. This design philosophy ensures reproducibility and prevents common pitfalls in RL research workflows.
train_fmu_gym addresses a critical gap in applying reinforcement learning to engineering systems by making existing simulation assets immediately usable for RL training. By reducing the technical barriers to FMU-based RL and providing a complete workflow from setup through evaluation, the toolchain accelerates research and enables practical deployment of RL controllers for complex multi-physical systems.
hide
For further information have a look at the accompanying paper:
J. Ultsch, K. Ahmic, and J. Brembeck,
“train_fmu_gym: A Functional Mock-up Unit-based Framework to Train Reinforcement Learning Agents for Multi-Physical Systems,”
IEEE Access, 2025, DOI: 10.1109/ACCESS.2025.3636787
Want to learn more or try it yourself?
Code & documentation (Helmholtz GitLab): https://codebase.helmholtz.cloud/dlr-vsdc/train_fmu_gym